안녕하세요, 끙정입니다.
오늘은 정형 데이터를 다룰 때면 흔히 마주치는 문제인 변수 인코딩(Feature Encoding)에 대해서 알아보겠습니다. 모든 인코딩 방법을 알아야 하는 건 아니기 때문에, 쉽게 쓸 수 있는 인코딩 방법 몇개만 소개하도록 하겠습니다.
가정.
범주형 변수는 데이터가 대부분 String으로 되어 있기 때문에 모델들은 이해하지 못합니다. 따라서 숫자로 인코딩을 해주어야 하는데, 인코딩 방식에 따라 알고리즘이 받아들이는 기준이 다릅니다. 인간은 정보를 보고 단번에 알아차릴 수 있지만, 컴퓨터는 일일이 다 알려줘야만 알아 먹죠. 정보 손실을 최소화하기 위해서는 데이터에 맞는 인코딩 방법을 써야 합니다. 그래야만 학습도 잘 되고, 설명력도 좋아집니다.
Nominal & Ordinal.
범주형 변수는 크게 Nominal(순서가 없는) 형식과 Ordinal(순서가 있는) 형식으로 나뉩니다. 아래 그림에서도 볼 수 있듯이 소와 개, 고양이는 특정한 개체가 우위에 있지 않습니다. 즉 순서가 없는 Nominal 데이터입니다. 반면에 매우 좋음, 좋음, 나쁨 등과 같은 범주는 우위가 있습니다. 따라서 Ordinal 데이터라고 할 수 있습니다.

Decision Tree가 숫자로 된 변수를 받아들였을 때.
트리 계열의 알고리즘들은 숫자로 된 변수를 받아들였을 때, 그것을 연속형 변수로 인식합니다. 예를 들어 [소, 개, 고양이]를 Label Encoding을 사용해서 [1, 2, 3] 으로 학습시킨다면, 트리 계열의 알고리즘들은 소보다 개가 크고, 개보다 고양이가 큰 개체라고 인식하게 됩니다. 이것은 트리 계열의 특징입니다. 따라서 트리 계열의 알고리즘에서 순서가 없는 Nominal 데이터를 라벨 인코딩(Label Encoding)을 통해 인코딩 하고 학습시킨다면, 성능이 잘 나오더라도(실험적으로는 잘 나올 때가 많습니다.) 제대로 정보를 학습하고 있다고는 볼 수 없습니다. 따라서 해당 범주형 변수가 Ordinal인지, Nominal인지 잘 살펴야 합니다.
Decision Tree가 원핫 인코딩(One-hot Encoding)을 받아들였을 때.
트리 계열의 알고리즘은 가지를 분기할 때마다 하나의 변수를 선택하여 정보 이득을 계산합니다. 반대로 선형 모델은 하나의 회귀 식에서 모든 변수의 영향을 동시에 계산하여 기울기를 줄여나갑니다. 원핫 인코딩은 하나의 변수를 여러개로 찢는 방식입니다. 변수 안에 카테고리가 10개면 1개의 변수가 10개의 변수로 늘어나는 것이죠. 그렇게 되면 하나의 변수에 대한 정보 이득이 10개의 변수로 찢어지기 때문에 해당 변수가 높은 정보 이득을 가질 가능성은 카테고리의 개수가 증가하는 만큼 줄어듭니다. 결국 알고리즘에 의해 잘 선택되지 않고 중요도도 낮아지게 되죠.
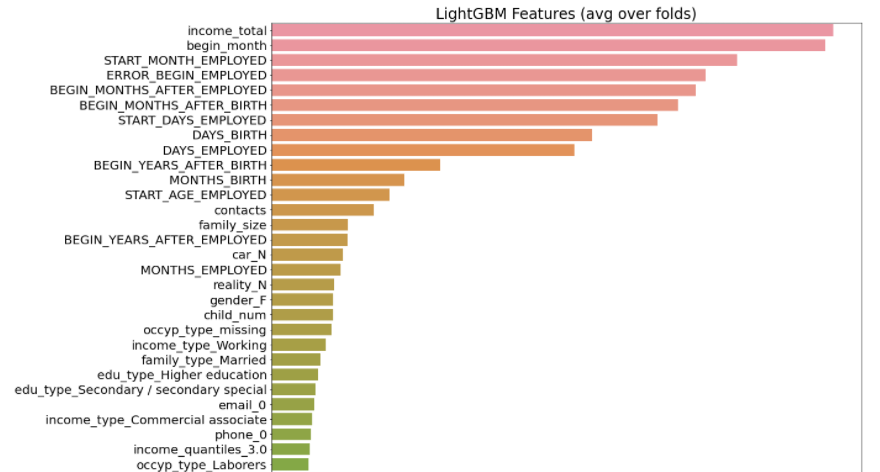
위 그래프는 제가 참여했던 한 경진대회에서 썼던 모델의 변수 중요도를 뽑은 그래프입니다. 상위 15개의 변수가 전부 연속형(수치형) 변수입니다. 범주형 변수 중에서 가장 높은 중요도를 냈던 변수는 16번째에 있는 'car_N' 입니다. 그 이유는 모든 범주형 변수들이 원핫 인코딩으로 변환이 되었고, 그만큼 정보 이득이 분산되어 중요한 변수로 작용하지 못했기 때문입니다. (해당 데이터는 변수가 무려 100개가 넘었습니다.)
선형 모델도 물론 변수가 많아질수록 과대적합 될 가능성이 높아진다는 단점이 있지만 이 문제는 규제(Regularization)를 통해 완화할 수 있습니다. 그러나 트리 계열의 문제는 과대적합을 넘어서 해당 변수가 제외되는 문제를 가져옵니다. 그렇기 때문에 트리 계열 알고리즘에서는 원핫 인코딩을 사용하는 것이 그다지 좋지 않게 받아들여지고 있습니다.
Binary Encoding, Ordinal Encoding, Hashing Encoding
그래서 준비한 인코딩 방법은 바로 이 3가지 입니다.
Binary Encoding는 이진법을 활용해 변수를 나누는 것으로 원핫 인코딩과 유사하지만 늘어나는 변수의 개수가 훨씬 적습니다.
Ordinal Encoding은 Ordinal 데이터에 쓸 수 있는 인코딩 방법으로, 순서를 지정해주는 것입니다.
마지막으로 Hashing Encoding은 변수를 더 높은 차원의 정수 공간으로 맵핑 시킵니다. 또한 관찰된 카테고리의 범주를 유지하지 않고 새롭게 맵핑하게 됩니다.(무슨 말인지 모르겠습니다.) 이또한 Binary Encoding과 비슷하게 원핫 인코딩보다 낮은 차원으로 인코딩할 수 있습니다.
바이너리 인코딩(Binary Encoding)
바이너리 인코딩의 방식은 아주 간단합니다. 카테고리에 대한 오더를 부여한 다음(바이너리로 바꾸기 때문에 오더는 의미가 없습니다.) 바이너리로 바꾸고, 이를 다시 원핫 인코딩의 방식으로 찢는 것입니다. 아래 그림의 순서로 작업이 이루어집니다.
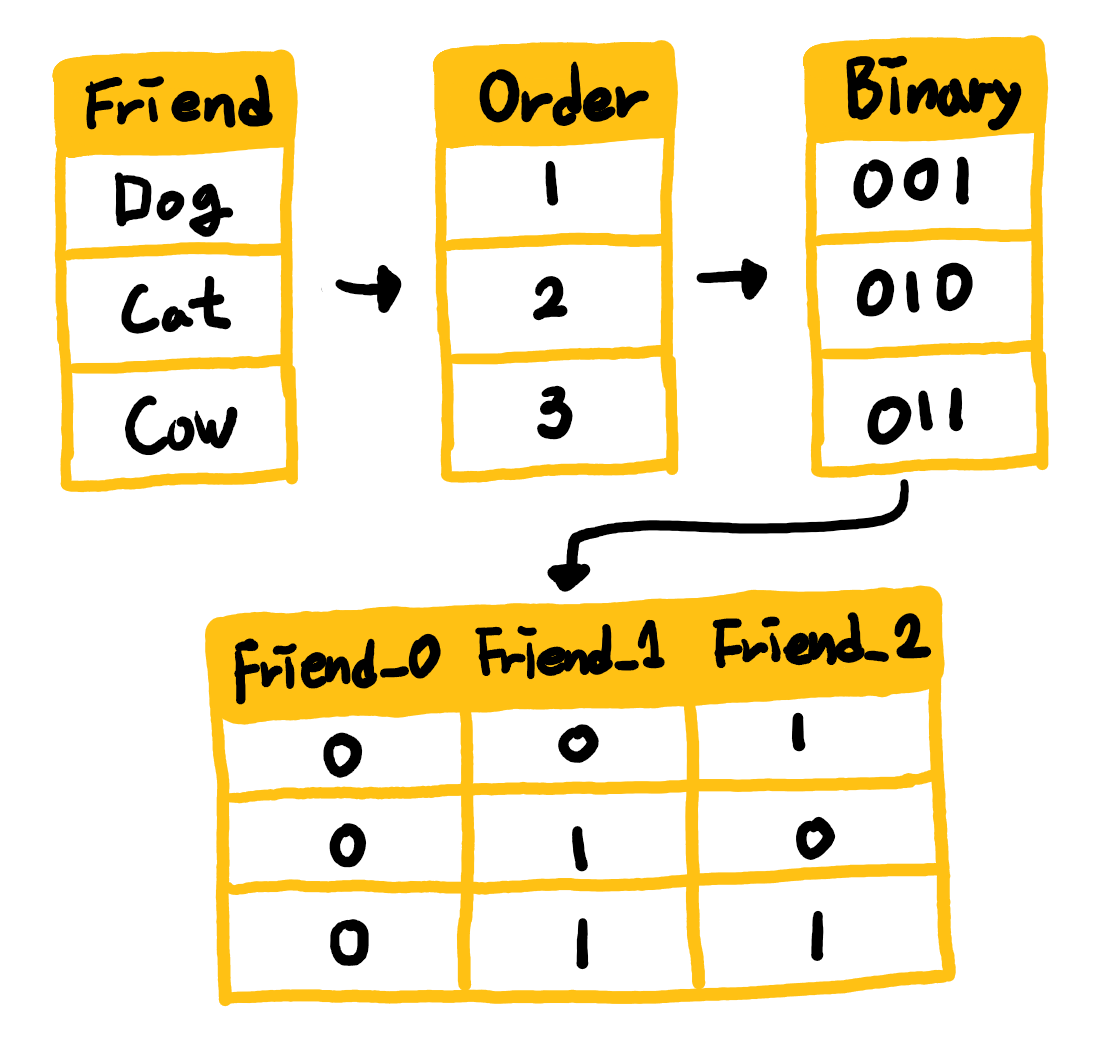
바이너리 인코딩의 장점은 원핫 인코딩의 방식을 취하면서 늘어나는 변수의 개수를 줄일 수 있다는 점입니다. 보통 카테고리가 15개가 넘어가면 바이너리 인코딩이 훨씬 효율적이라고 합니다. 그러나 제 생각에는 카테고리가 4개만 넘어가더라도 원핫 인코딩보다 바이너리 인코딩의 변수가 작아지기 때문에 4개 이상만 되어도 바이너리 인코딩을 사용하는 것이 나을 수 있겠다고 판단하고 있습니다.
from category_encoders import BinaryEncoder
import pandas as pd
from sklearn.datasets import load_boston
bunch = load_boston()
y = bunch.target
X = pd.DataFrame(bunch.data, columns=bunch.feature_names)
enc = BinaryEncoder(cols=['CHAS', 'RAD']).fit(X, y)
numeric_dataset = enc.transform(X)
오디널 인코딩(Ordinal Encoding)
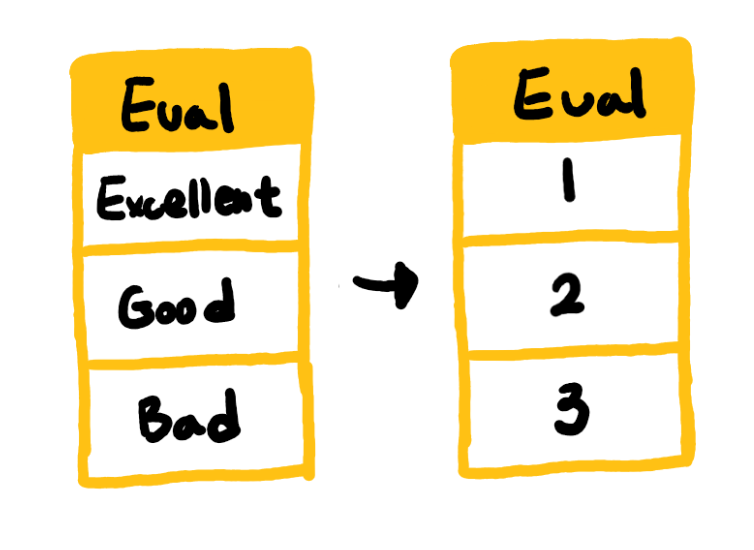
오디널 인코딩은 해당 범주형 변수가 Ordinal 데이터일 때 가능한 인코딩 방식입니다. 라벨 인코딩과는 다르게 순서 정보를 담을 수 있다는 것이 장점입니다.
income_type_encode = {'Commercial associate' : 0,
'State servant' : 1,
'Working' : 2,
'Pensioner' : 3,
'Student' : 4}
X['income_type_encoded'] = X.income_type.map(income_type_encode)
해싱 인코딩(Hashing Encoding)
해싱 인코딩은 하나의 변수만을 인코딩하지 않습니다. 결과물만 살펴보면 PCA와 매우 비슷하게 느껴질 수 있습니다. 다수의 변수를 한 번에 다차원 공간에 맵핑시켜서 인코딩하는 방식입니다. 그렇기 때문에 단점이 명확히 존재합니다. 바로 해석의 용이성이 떨어진다는 점입니다.

from category_encoders.hashing import HashingEncoder
import pandas as pd
from sklearn.datasets import load_boston
bunch = load_boston()
X = pd.DataFrame(bunch.data, columns=bunch.feature_names)
y = bunch.target
he = HashingEncoder(cols=['CHAS', 'RAD']).fit(X, y)
data = he.transform(X)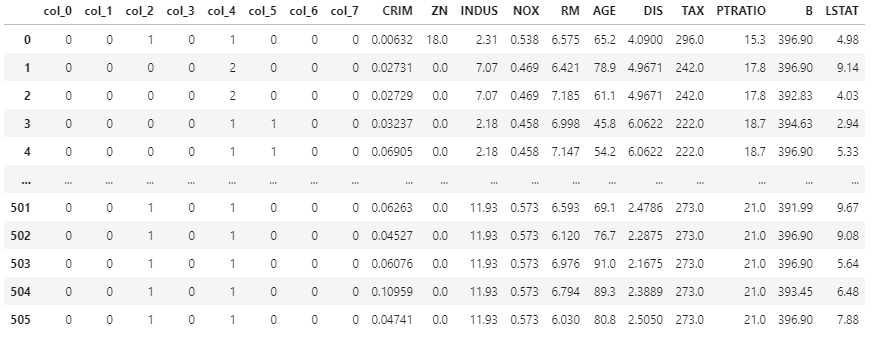
그 외에도 많은 인코딩 방식이 있습니다.
여기서 다루지 않은 원핫 인코딩(One Hot Encoding), 라벨 인코딩(Label Encoding)도 있고, 헬멋 인코딩(Helmert Encoding)이나 민 인코딩(Mean Encoding), 백워드 디퍼런스 이코딩(Backward Difference Encoding) 등등. 찾아보면 끝도 없는 곳이 바로 인코딩인 것 같습니다.
아래 글들을 매우 많이 참고했습니다. 다른 인코딩 방식 또한 서술되어 있으니 참고하세요! :)
https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
All about Categorical Variable Encoding
Most of the Machine learning algorithms can not handle categorical variables unless they are converted to numerical values and many…
towardsdatascience.com
https://contrib.scikit-learn.org/category_encoders/index.html
Category Encoders — Category Encoders 2.2.2 documentation
Category Encoders A set of scikit-learn-style transformers for encoding categorical variables into numeric with different techniques. While ordinal, one-hot, and hashing encoders have similar equivalents in the existing scikit-learn version, the transforme
contrib.scikit-learn.org
https://innovation.alteryx.com/encode-smarter/
Encode Smarter: How to Easily Integrate Categorical Encoding into Your Machine Learning Pipeline
Automated feature engineering solves one of the biggest problems in applied machine learning by streamlining a critical, yet manually intensive step in the ML pipeline. However, even after feature engineering, handling non-numeric data for use by machine l
innovation.alteryx.com
'데이터 사이언스 > 데이터 사이언스' 카테고리의 다른 글
| 오버샘플링 기법(Over Sampling Methods) (0) | 2021.05.07 |
|---|---|
| 지니(Gini) vs 엔트로피(Entropy) 그리고 정보 이득량(Information Gain) (0) | 2021.04.30 |
| 트리 기반 메서드(Tree Based Method) (0) | 2021.04.27 |
| 엑스트라 트리(Extra Trees) vs 랜덤 포레스트(Random Forest) (0) | 2021.04.26 |
| GBM vs XGB vs LGBM vs CATB (4) | 2021.04.25 |




댓글